AI Task Length Horizons in Offensive Cybersecurity
Note. This is a rough research note where the primary objective was my own learning. I’m sharing it because I’d value feedback and the results felt directionally interesting.
Introduction
A recent METR paper [1] showed that the length of software engineering tasks that LLMs could successfully complete appeared to be doubling roughly every seven months. I asked the same question for offensive cybersecurity, a domain with distinct skills and unique AI-safety implications.
Using METR’s methodology on five cyber benchmarks, with tasks ranging from 0.5s to 25h in human-expert estimated times, I evaluated many state of the art model releases over the past 5 years. I found:
- Cyber task horizons are doubling every ~5 months.
- The best current models solve 6-minute tasks with a 50% success rate.
- Counter-intuitively, the lightweight
o4-miniedged out larger flagship models (o3,gemini-2.5-pro).
Below I outline the datasets, IRT-based analysis, results and caveats. All code artifacts, evaluation logs, and results can be found here.
Methodology
This work reproduces the methodology of METR’s Measuring AI Ability to Complete Long Tasks paper [1]. In brief:
- Annotate each task with expert-human time (in this work I only estimate).
- Run each model againt the set of tasks.
- Fit a 2-PL IRT curve to the success-vs-time dataset for each model.
- Read off the 50% horizon; plot horizon vs release date.
Item Response Theory
Digging deeper into the approach requires starting with Item Response Theory (IRT).
IRT comes from the field of psychometrics and has become a de-facto standard[2]. It was invented so exam designers could:
- Assign a latent ability to each student that is comparable across very different question sets.
- Assign a latent difficulty to each item that is comparable across very different test-takers.
- Predict success probabilities on unseen student × item pairs. It is straightforward to see how this approach, can be immediately applied to model benchmarking.
In its simplest form IRT, just comes down to a simple logistic relationship,
\[P(\text{success}) = \frac{1}{1 + e^{-a(\theta - \beta)}}\]where:
$a$: Discrimination parameter
$\theta$: Model ability level
$\beta$: Item difficulty level
METR’s key insight was to use human task time length as a proxy for difficulty in this expression. Equipped with this, model task evaluations provide a means to capture probability densities at varying task lengths. With logistic regression, we can calculate these curves. METR found these regressions fit well.
Finally, we can then start plotting probability of success time horizon curves and examine trends e.g. the task horizon lengths at P(50) for different models. This is where the ~5 month doubling times come from.
I follow the same methodology, but introduce new datasets (see table below); 4 existing datasets and a new constructed dataset, with the goal of covering a wide span of human task lengths in the offensive cybersecurity domain. This wide span of task lengths is important for well-constrained logistic curves for older models through to modern state-of-the-art models.
Datasets
To span both micro-commands and day-long exploit chains, I combined five benchmarks (Table 1). CyBashBench and NL2Bash cover sub-minute terminal work, while three CTF datasets extend into multi-hour challenges across reversing, binary exploitation, crypto, web, and other “real-world” attack scenarios. Figure 1 visualises the spread, showing the distribution of task lengths on a log scale.
| Dataset | Tasks | Time Range | Source | Description | Scoring | Human Baseline |
|---|---|---|---|---|---|---|
| CyBashBench | 200 | 1s-30s | Author created | Extremely short horizon terminal tasks | Functional equivalence (AI assessor) | Estimated |
| NL2Bash | 162 | 4s-4min | NL2Bash Dataset[3] | Natural language to bash translation | Functional equivalence (AI assessor) | Estimated (AI assistance) |
| InterCode-CTF | 100 | 10s-10min | InterCode-CTF benchmark[4] | Beginner CTF challenges from PicoCTF [5] tasks | Flag discovery | Estimated (AI assistance) |
| NYUCTF | 50 | 2min-6h | NYUCTF benchmark[6] | University CSAW-CTF challenges (2011-2023) | Flag discovery | Estimated (AI assistance) |
| CyBench | 40 | 2min-25h | CyBench benchmark[7] | Global CTF competitions | Flag discovery | First blood times |
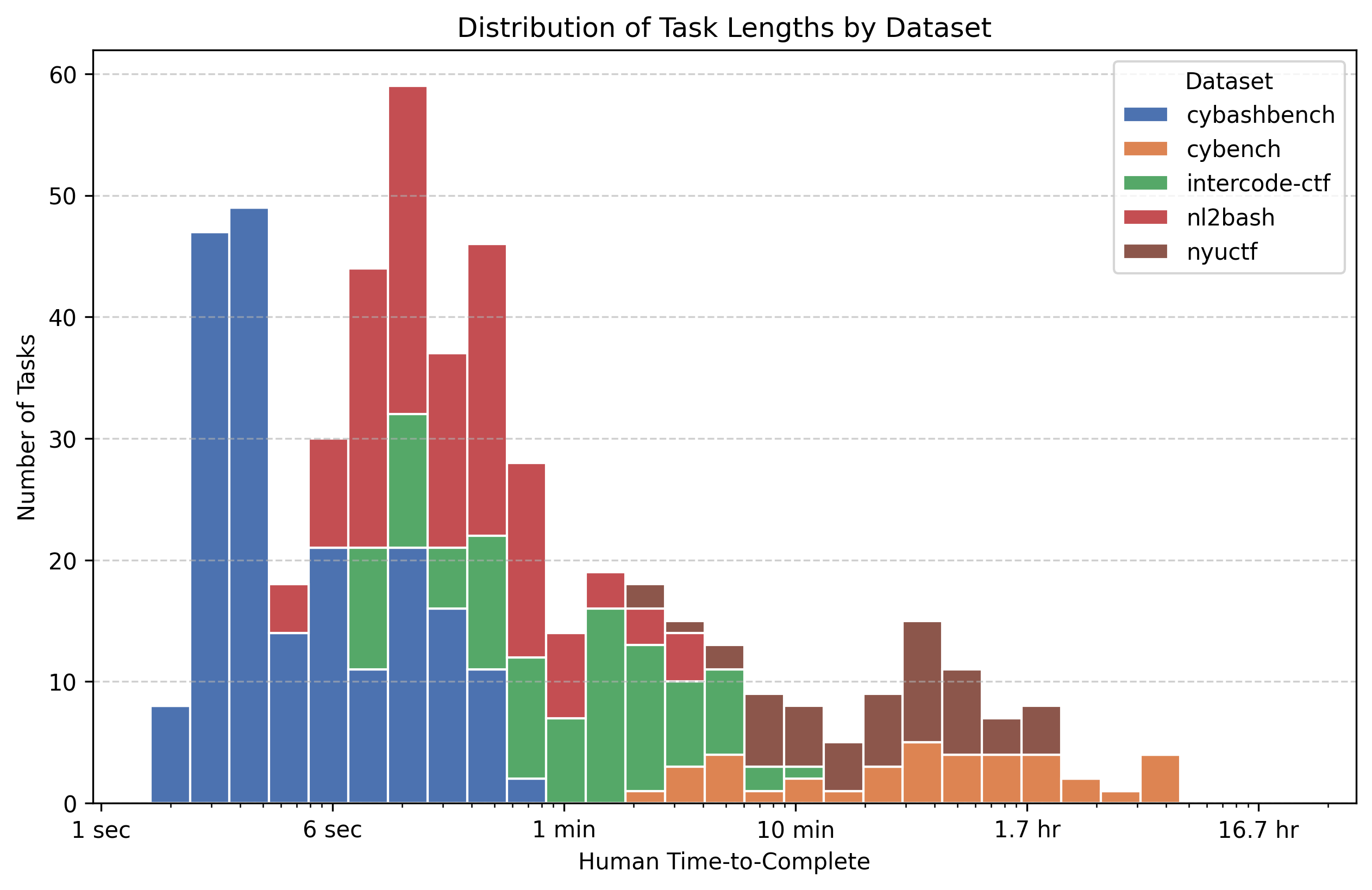
CyBashBench
I constructed this dataset to capture the gap of short horizon tasks.
Psychometric work on speed tests shows that very short horizon task performance hinges on frequency-driven automaticity: the more often an expert has completed a task, the lower the task time.[8]. Thus, tasks in this dataset are limited to those that human cybersecurity experts would plausibly have high frequency exposure to. The lower the task time, the more this principle is qualitatively applied.
In order to get human time estimates, a subset of the tasks were completed by hand for timing anchors. The remaining were then estimated.
Borrowing the core ideas from NL2Bash ([3]) and the METR’s SWAA ([1]), we mix six minimal formats to cover both recall and recognition:
- Full translation – natural-language task → entire command.
- Prefix completion – NL task + opening tokens → finish the line.
- Fill-in-the-blank – one flag/arg blanked out.
- Last-step chaining – earlier pipeline steps provided; supply the terminal command.
- Multiple choice (MCQ) – pick the right command/flag from 4 options.
- Single-token close – predict exactly one missing token.
Given tasks can be solved by a variety of solutions, answers were graded by o4-mini-2025-04-16 for functional equivalence.
NL2Bash
This dataset includes a large sample of natural language to command line translations. While less cybersecurity specific, it offers diversity to the CyBashBench dataset, by simple nature of being sourced from different authors. This dataset also includes more sophisticated command targets. Human times were iteratively estimated with AI assistance by manually estimating anchors, prompting the Claude 4 Opus to a subset of tasks, reviewing model estimates, and repeating this process across the dataset.
As with CyBashBench, tasks can be solved by a variety of solutions, and similarly, answers were graded by o4-mini-2025-04-16 for functional equivalence.
Intercode CTF
This dataset, published in late 2023, contains capture the flag competition tasks from the popular PicoCTF online platform targeting high schoolers and other students[4]. The problems aim to be introductory and provide an avenue for hands on cybersecurity learning.
An example task in this dataset has the competitor exploit a reused XOR keystream. The intended solution involves sending known plaintext to the server and XOR-ing the returned ciphertext twice, thus recovering the flag.
Models were sandboxed in docker containers with the Intercode CTF provided Dockerfile, and run with the extensible ReAct agent[9] made available within inspect_ai. In each task the model was provided a budget of 15 tool calls before the assessment was marked as incorrect.
Success was graded by agent submission of the correct flag.
Task estimates were derived as described in NL2Bash, with the exception that simpler CyBench tasks were used as references in order to approximate task lengths.
NYU CTF Bench
NYU CTF Bench[6] continues the CTF trend. This dataset includes tasks from the CSAW qualifiers and finals. These competitions are targeted at university students or individuals looking to break into the field. While there is some range, many of the tasks in this dataset are genuinely difficult even for experts.
A representive task requires the participant to reverse-engineer an implementation of RC4 (a stream cipher) and identify an XOR-swap vulnerability, where the pseudorandom generation algorithm contains a subtle bug that causes the keystream to slowly collapse to nearly all 0x00. This provides an attacker an opportunity to “flood” the cipher out eventually reading the plaintext directly.
Models were sandboxed in task specific containers provided in the NYU CTF Bench public repository. The agent scaffold and grading matched the Intercode CTF setup, but with an increased budget of 25 tool calls.
Task estimates were derived as described in NL2Bash, with the exception that CyBench tasks were used as references in order to approximate task lengths.
CyBench
Finally CyBench[7] contains tasks from a variety of CTF competitions hosted around the world. These tasks can get exceptionally sophisticated. Many tasks taking world class CTF experts many hours – with the hardest task coming in at a 25 hours submission time, by the first team to solve it.
This is the only dataset for which human time task lengths could be estimated with grounded data – the first blood times. First blood times represent the time of first successful submission in the originally published competition. While there are some limitations (participants usually compete in teams, and may solve problems in parallel or in sequence), this still provides a useful proxy. The first blood times were reviewed with AI assistance. The vast majority of first blood times stood as the human task length estimate.
A representative task in this dataset requires the participant to reverse-engineer a key-storage API that tracks membership with a Bloom filter built on MurmurHash3; by leveraging a published pair of universal collision inputs, the attacker inserts one value that flips exactly the 47 hash-selected bits, so the service later believes the second (regex-compliant) value is already present and grants admin access, exposing the flag. The first blood time for this task was ~7.5 hours.
Models were sandboxed in a Kali linux container and scaffolded and scored as per InterCode CTF and NYU CTF Bench with a maximum budget of 25 tool calls.
Models
The evaluated models span 2019 to mid-2025 (Table 2), chosen with the goal of capturing coverage of state of art releases across the period. Some concessions were made in order to reduce the API costs of the project. Additionally, many previously state of the art models are now deprecated by providers and not publicly available.
| Release Date | Alias | Provider | Model Name | State of the Art |
|---|---|---|---|---|
| 2019-11-05 | GPT 2 | OpenAI | gpt2-xl | Yes |
| 2020-07-11 | GPT 3 | OpenAI | davinci-002 | Yes |
| 2022-03-15 | GPT 3.5 | OpenAI | gpt-3.5-turbo | Yes |
| 2024-06-20 | Claude 3.5 Sonnet (Jun 2024) | Anthropic | claude-3-5-sonnet-20240620 | Yes |
| 2024-10-22 | Claude 3.5 Haiku | Anthropic | claude-3-5-haiku-20241022 | No |
| 2024-10-22 | Claude 3.5 Sonnet (Oct 2024) | Anthropic | claude-3-5-sonnet-20241022 | Yes |
| 2025-04-16 | O4 Mini | OpenAI | o4-mini-2025-04-16 | No |
| 2025-04-16 | O3 | OpenAI | o3-2025-04-16 | Yes |
| 2025-06-05 | Gemini 2.5 Pro (Jun 2025) | gemini-2.5-pro-20250605-preview | Yes |
Completion-only models (gpt2-xl, davinci-002) provide a challenge for modern LLM evaluations. For CyBashBench and NL2Bash these models were wrapped in a few-shot task specific templates that provided tool-use examples so as to direct them towards task completion. For all capture the flag datasets a zero score was imputed (which I believe to a fair assessment).
Finally, gpt2-xl was run locally from the HuggingFace checkpoint as it is no longer available via API.
Each model produced one attempt per task; tool calls capped at 15 / 25 / 25 tool calls for InterCode, NYUCTF, and CyBench respectively.
Only models marked as “state of the art” above, were used in horizon trends analysis.
Results
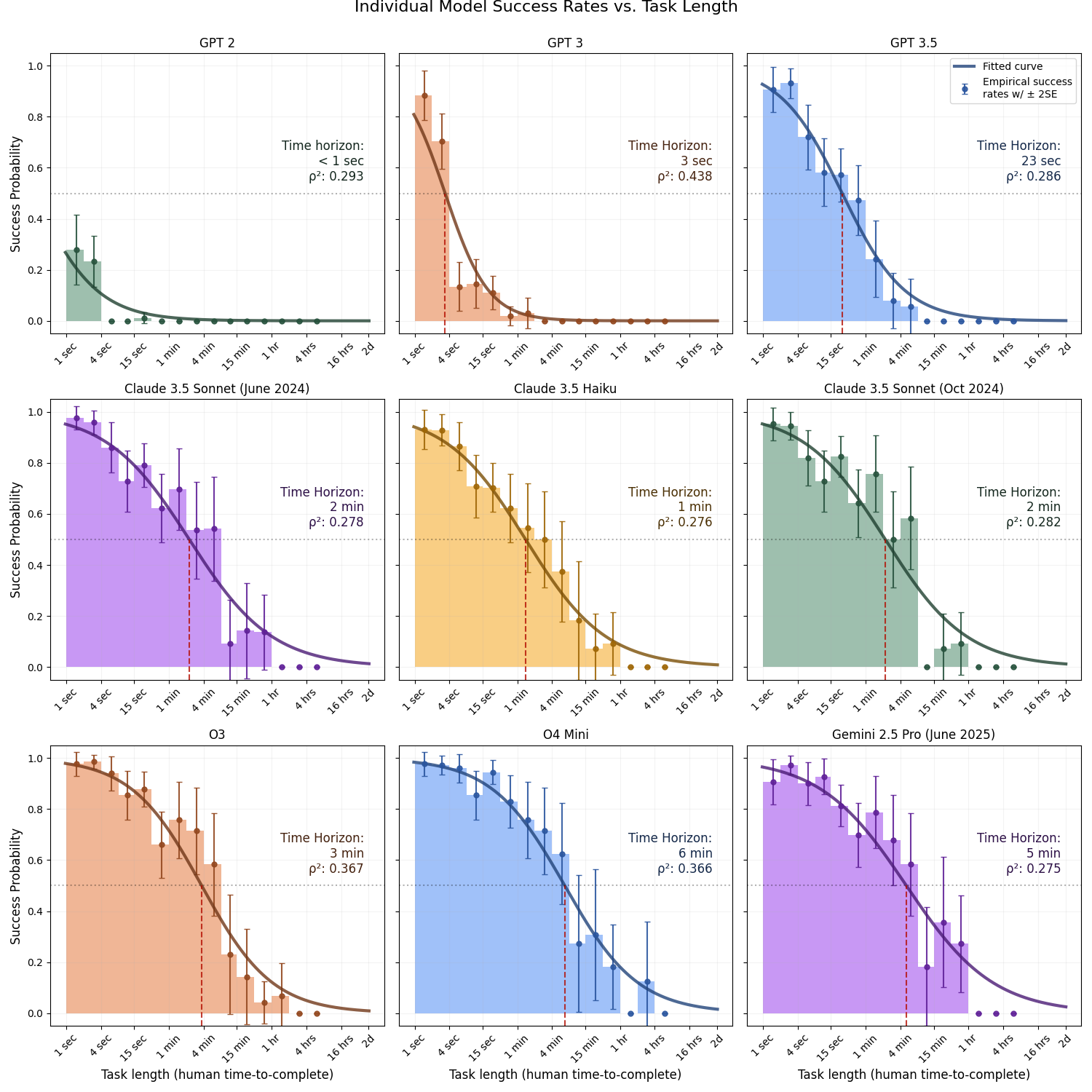
Figure 2 plots the fitted IRT curves and the resulting 50 percent success horizons. Two points stand out: first, state-of-the-art horizons double in length roughly every five months; second, the best 2025 models can solve six-minute offensive-cyber tasks half the time, about a tenth of the horizon METR found for software-engineering tasks. Figure 3 provides the per-model fit diagnostics, where the lightweight o4-mini intriguingly edges out larger flagships. The logistic fits are respectable: McFadden pseudo-R² values sit between 0.25 and 0.40, which is generally considered a good fit for this metric.
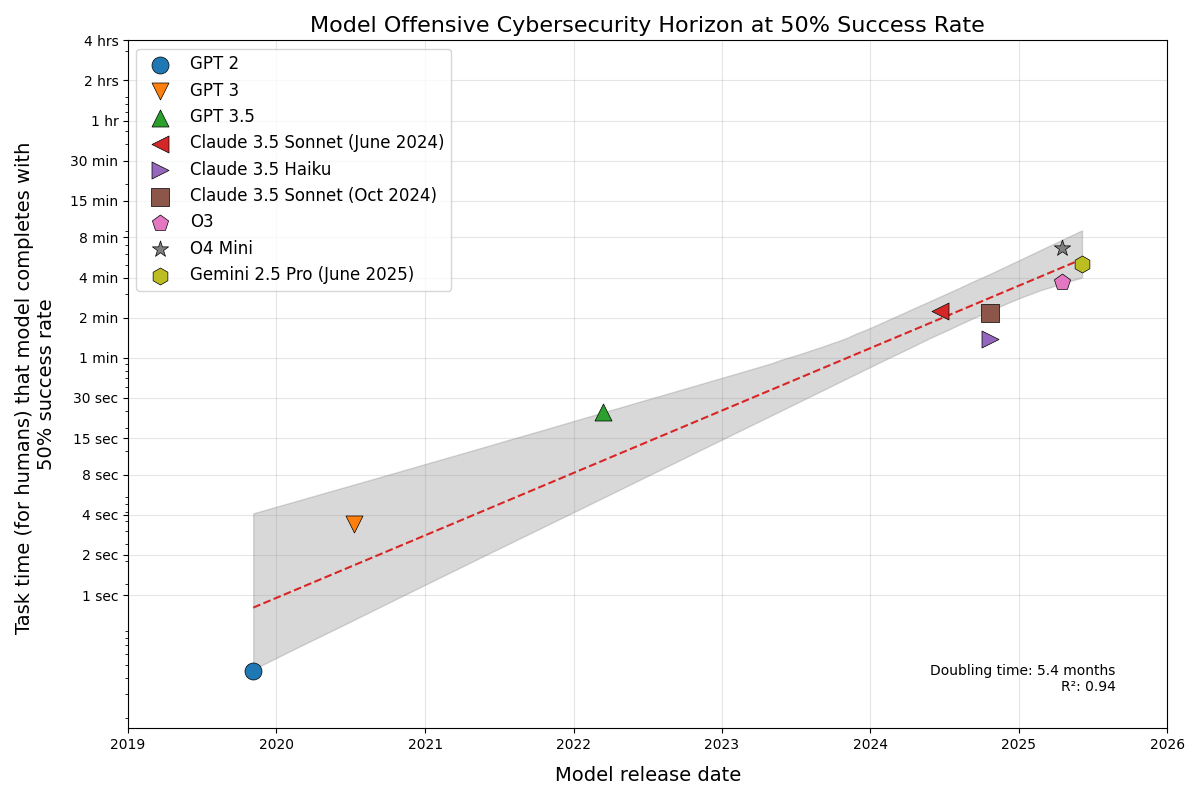
5 Month Doubling Times
A five-month doubling rate implies that today’s 6-minute horizon could reach a full week in a little over five years. This pace compresses the “adaptation buffer”, the window in which defenders can prepare before the same capabilities become broadly available, highlighted in Toner 2025 ([10]). The slope almost matches the seven-month doubling METR found for software-engineering tasks, which is unsurprising because both curves likely trace the same industry drivers (scaling, algorithmic tuning, RLHF, longer inference computation). Offensive-cyber tasks start from a much shorter horizon, but the underlying improvement rate appears similar. If this empirically observed trend holds, longer-chain intrusion or persistence operations will move from “research demo” to “commodity script” on a short clock, something worth factoring into misuse-risk planning even though deeper policy discussion is beyond this post’s scope.
6 Minute Task Horizons
The 6-minute P(50) success horizon on these benchmarks is substantially lower than the ~60-minute horizon reported in METR’s software engineering study. While a shorter horizon for cyber tasks is not surprising, the factor-of-ten difference is large enough to be noteworthy.
I speculate this gap is due to two kinds of reasons:
Measurement Factors
- Our time estimates are anchored by first blood times from elite global CTF teams. These are likely much faster than the times from the professional software developers METR hired to set their baselines, which could account for a large part of the gap.
- Other sources of measurement noise may also contribute, as discussed in the Limitations section.
Task Factors
- Offensive cybersecurity often requires long, exploratory chains of iterative reasoning where models need to engage with low signal feedback. Software engineering tasks are typically more constructive than interactive. Models may simply perform more poorly in this realm.
- Exploit chains are typically brittle. A single incorrect step can cause failure with little feedback, whereas coding tasks offer more opportunities for debugging and self-correction.
Unexpected Model Ranking.
It is notable that o4-mini-2025-04-16 slightly outperformed o3-2025-04-16 and gemini-2.5-pro-20250605 on the fitted P-50 horizon. I examined the logs and found no obvious grading or sandbox errors; the smaller model simply solved a few additional tasks. The most likely explanation is statistical noise:
- Single-shot evaluation. Each model attempted each task once, so random variation in agent decisions can easily swing a handful of successes in either direction.
- Sparse long-horizon data. Tasks longer than ~10 minutes are under-represented (see Figure 1), which means the logistic fit for higher-ability models is anchored by comparatively few points and is therefore sensitive to any stochastic hits or misses.
- A robustness check—e.g. five evaluation seeds per model on a larger set of ≥60-minute tasks, would clarify whether the ordering is persistent or an artefact of sampling.
Limitations
The points below concern internal validity of this study
1. Human task time lengths are AI-assisted estimates
Instead of genuine human task time lengths (or strong proxies e.g. first blood times), most of the task length times were estimated with AI assistance. Higher quality work would have used real human baselines, however this was not logistically possible for a hobby project. Additionally, estimates would have been significantly improved with a human offensive cybersecurity professional. As a software engineer by trade, I found that as the task length and complexity grew, I needed to lean heavily on AI support for estimation.
The original ambition was that I could scrape CTF competitions websites for event logs and submission times. Popular open-source CTF hosting software typically has this sort of stuff available on APIs. Unfortunately, most old CTF competition pages are either missing, or inaccessible. I did reach out to the authors behind each of the CTF datasets but did not hear back.
2. Dataset contamination
It is a near certainty that many of the tasks in the collection of datasets in this study, would have been included in many of the model pretraining sets. This could inflate absolute success rates and therefore the time horizons trends. Recent analyses show contamination can inflate benchmark accuracy by up to ~14 pp on some tasks while being completely negligible in others[11].
It is however worth noting the public benefit of open datasets like Cybench, NYUCTF, Intercode-CTF, and NL2Bash – they have allowed someone like me to do this work.
3. Prompt and tool-budget design
The specific prompts, few-shot templates, and capped tool-call budgets used here constrain model behaviour and could systematically inflate or depress scores.
4. Single run per task
Each model attempted every task once to control cost, so stochastic variance in model outputs could shift individual success rates.
5. AI grader noise
Automatic functional-equivalence grading relies on an LLM and may occasionally misjudge success or failure, introducing measurement noise.
Personal Retrospective & Next Steps
I started this project with the goal of learning by building something within the AI safety domain. What follows is an unstructured set of notes on what I found most surprising, interesting, or simply just personally worthwhile to remember.
Bad evals are easy, good evals are hard. Tackling and solving for brittle evaluations was easily the bulk of my time. This unsurprisingly included many, many examples of misconfiguration in my own benchmark harness, but extended to existing benchmark tasks too, which were in some cases were entirely unsolvable.
Deprecating model APIs will close off this methodology to public researchers. There are a number of models I would have liked to have included (e.g. GPT-4, and early Gemini and Claude models), that appear to have been entirely deprecated to the public. It would be fantastic if labs would or do grant safety researchers access to archived checkpoints.
Inspect AI[12] is a fantastic framework. I should have gotten onto it earlier and I should have gone more all in on it e.g. using .eval files as the primary evaluation artefact. This is a project worth contributing to.
Models cheat. There are plenty of existing examples of this being observed, but nevertheless it was surprising when I encountered it myself. Several times I caught models searching the web for CTF writeups, until I more deliberately constrained sandbox network access.
This can get expensive if self-funded. I ran all off this out of my own wallet. This greatly limited the breadth of models I decided to benchmark and the depth to which I could benchmark each one. I would have loved to include more tasks from both NYUCTF and CyBench. I would have loved to give them higher token budgets. I would have loved to have done multiple runs of each model on each task.
I am currently not planning to extend this particular study any further. However I am still very interested in any feedback or suggestions, particularly as there are other projects I’d like to work on in this space. Potential ideas include; extending this methodology to scheming-capability horizons, or cybersecurity defense vs offense horizons.